Python Strings¶
Read time: 24 minutes (6036 words)
Remember those simple looking strings we started using in our first
exposure to Python (in Hello, World). Well, there is more to them than
meets the eye!
Strings are objects¶
Well, that is dumb! Everything in Python is an object, and we will learn how to build our own objects (simple ones) after our break. For now, we just want to explore the tools we get with Python that help us manipulate strings.
Strings are a sequence of characters. OK, what is a character (don’t
answer that!).
Formally, characters we use normally come from the ASCII table of symbols.
This table was designed by Americans, for use by Americans, but the table went
global when the Internet became popular. Unfortunately, it is not up to the
task of displaying symbols used by other countries, so it is (slowly) being
replaced by another encoding called Unicode. For our course, we will stick
with ASCII.
Here is the ASCII table:
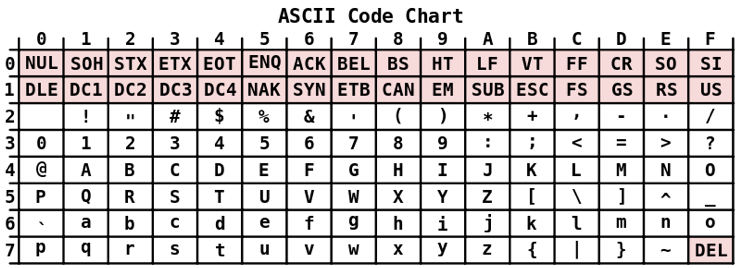
Looking at this table, we see the code used for each character (written as a hexadecimal number that can be stored in a single byte). For instance, the code for the capital letter “Q” is 51 (in hexadecimal). We sometimes write this as “0x51” in programming.
Here is a string we can play with¶
my_string = "roie r black"
We already know we can print this out. What else can we do with it?
>>> print(my_string)
roie r black
Finding the length of the string:
>>> len(my_string)
12
This result shows that the string has 12 characters in it. Sometimes, the number will not look right, and that may be because the character is unprintable. If you look at the top few rows in the ASCII table you will see several special characters that have meanings in certain situations, but which have no “visual” representation (like “CR”, which stands for “carriage return” and “LF”, which stands for “line feed”).
Since a string has a length, you might suspect that we can reach into the string and extract individual characters, and you are right:
>>> my_string[5]
'r'
Remember that index numbers start at zero and reach up to len(my_string)-1.
We can use this fact to set up loops that pass over each character in the string. Rather than make you set up a special variable to count, Python lets you set up a simpler loop:
>>> for ch in my_string:
... if ch == 'r':
... print("found an 'r'")
...
found an 'r'
found an 'r'
Looks about right! Using this scheme, we do not worry about setting up indexes that might get out of range, Python takes care of that mess for us!
>>> my_string[15]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
Doing math with strings¶
We have already seen this:
>>> test = 'test'
>>> string = 'string'
>>> print(test + ' ' + string')
test string
Here is another example:
>>> print(test*2)
testtest
>>> print((test+' ')*2)
test test
WHat really got printed on that last example? Here is a way to find out:
>>> print('"' + (test + ' ')*2 + '"')
"test test "
Do you see where that extra space came from?
test += 'junk'
print(test)
testjunk
We need to be a bit careful, because stings are immutable. So how did we add something to the existing string. Simple! Python threw the old one away and created a new one. Try this:
>>> test[2] = 'x'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Well, that is annoying. How can I change the characters in the string? We will see that later
String methods¶
Since strings are those funny “object” gizmos we have talked about, they have a bunch of internal “methods” they know about. Here is a selection of those that are available:
isalnum() - is the string just made up of letters and numbers
isaplha() - is the string only made up of letters
isdigit() - is the string made up of only digits
islower() - is the string only lower case letters
isupper() - guess!
These can be useful when error checking input you got from those annoying human operators who like to see if they can break your program.
String conversion methods¶
There are a few methods we can use in error checking, to make our life a bit easier:
>>> test1 = 'RoIe'
>>> test2 = "Roie"
>>> test1 = test1.lower()
>>> test2 = test2.lower()
>>> print(test1 == test2)
True
Note
Notice what we are doing here. We are not trying to reach into an existing string and modify it directly. Instead, we use the old string and modify it (actualy, a copy of it), then store the new result back in the same variable container. The old string is gone, and replaced by the new one.
Here I am converting the strings to all lower case to get rid of the capitalization issues. My goal is to see if they user entered ‘roie’ in any format. Now I can see how that might be done!
We have see other useful string methods:
strip() - remove any “whitespace” characters from the sides of the string
lstrip() - remove whitespace from the left side only
rstrip() - remove whitespace from the right side only
There are other variations of these methods, but I seldom find a good use for them.
String searching¶
Often, we need to check strings to see if they contain substrings. Python
has several tools for this:
endswith(pattern) - returns True if the string ends with the text specified
startswith(pattern) - returns True is the string starts with the pattern
find(pattern) - returns the index of the first occurrence of this pattern in the string (or -1 if not found)
replace(pattern1, pattern2) - replace each occurrence of pattern1 with pattern2
Remember that all of these return new strings if they modify the old string, so you need to save (or use) the result.
Breaking up strings¶
Here is a typical problem, we need to take a string form of a date and break it up into its parts:
>>> date = "December 7, 1941"
>>> parts = date.split()
>>> print parts
['December', '7,', '1941']
This is interesting. The split method, with no parameter, breaks up a
string at space boundaries. Notice that we ended up with the comma in the day
number chunk. Can we get rid of that?
>>> parts[1] = parts[1][:-1]
>>> print(parts)
['December', '7', '1941']
Remember that a string is just a special kind of list, this one a list
of characters. We can use the subscripting notation to access parts of the
string. Remember the -1 index refers to the end of the string. We need to study
this notation a bit further:
>>> test = "thisisalongstring"
>>> test[0:4]
'this'
>>> test[11:]
'string'
>>> test[11:-1]
'strin'
>>> test[11:-2]
'stri'
As usual, the notation is like the range where the first index is the
number (starting with zero) of the character we want to start with. The last
number is one more than the ending index.
If we leave off the first index, it is assumed to start at zero, if we leave off the last index, it ends up being the length of the string, which is one more than the last index.
Formatting with strings¶
Python 3 adds a few new tricks we can do with strings to format our output.
We have already seem the old python way of using a string with special placeholders for data:
data = "This is an int: %d, and a float: %f" % (3,3.14)
This is a simple string substitution scheme that Python 3 want to eliminate. In its place, here is the new scheme:
>>> data = "This is an int: {0}, and a float: {1}".format(1,1.5)
>>> print(data)
This is an int: 1, and a float: 1.5
Python is smart enough to figure out how to display each thing, integer or float.
Extending this, we have a lot of power to specify exactly how we want the numbers to be displayed:
>>> mem = 624.253
>>> units = 'GB'
>>> data = "You have this much memory: {0:.1f} {1}".format(mem,units)
>>> print(data)
You have this much memory: 624.3 GB
There is much more to this formatting stuff. We will look at more of this in a later lecture.
