Simple C++ Functions¶
Read time: 34 minutes (8677 words)
See also
Text: Chapter 6
What is a function, anyway?
Simple! Just a named box with some code in it!
We put code in a box so we can use it over and over if we want. We can also make that code return some value if we like. We can also hand the code in the box a few parameters to work with so it can do different things depending on the values of those parameter things we provide.
You are familiar with this concept, you use it all the time when you pick up a calculator and punch one of those function keys. The number in the display is a parameter handed to the function whose name is on the button. The value returned from the function is the new value in the display after you hit the button. If the display has a four in it and you hit the square root button, the new value will be two!. Right?
Functions have been a fundamental part of programming for a long time. They are the way we break big programs down into smaller parts that are easier to solve. We combine a number of smaller parts to build bigger constructions that end up building big programs. Done right, we have collections of well crafted functions we can pick off of a shelf and use over and over in new projects. This is the holy grail of programming: Reusable parts!
Note
There is one huge problem with this goal. The NIH problem. NIH stands for “Not Invented Here”. It is a disease programmers get that makes them think they can write a better version of a component than anyone else, so rather than use a perfectly good component, they go off and write one of their own. This problem is often found in professors who claim they have to write their own versions so they can explain the code to students. Wait, that sounds like me! Yikes!
Writing C++ Functions¶
Most C++ Functions end up in separate files. Often a single file will contain more than one function. Usually the name of the file is the name of the main function, and any other functions in that file support that main function. As an example, lets rewrite of old classic “Hello, World” so it uses a Message function in a separate file. Along the way, we will show the classic way we craft a C++ program constructed using separate files.
The main program file¶
Every C++ program has to have a main function. This is the function where the program will start. To keep this example simple, here is our starting point:
#include "Message.h"
int main(int argc, char * argv[]) {
message(void);
}
This example is not using good style, since it does not include a header identifying the program, and programmer. More on that later.
It does include an include line, but not one that allows us to do input and output. The reason for that is simple, this main routine does no input or output. Instead, that operation will be done elsewhere. We are going to call a function that lives in another file, and that function is described in the header file named in the include line shown in this code. The quotes around the file name tell the compiler that this header file is located in the directory where the compile command was issued, not in the system directory where iostream was found in our earlier example.
The actual file containing the message function looks like this:
#include <iostream>
#include "Message.h"
void message(void) {
std::cout << Hello, World << std::endl;
}
Notice that this file includes our old familiar iostream line, and it also includes the same include line found in the main program source code line earlier. Why?
The reason is simple.
We want to make sure that both files will connect properly. One file contains the message function, and the other file uses the message function. By including the header file in both, the compiler can make sure that both will properly reference the function correctly, and there will be no surprises when we hook up the two chunks of code. This kind of check is what makes it safe for two different programmers to go off and work on the two parts of the program independently!
Parameters¶
Parameters are a very important part of the business of designing functions. They allow us to create containers of code that can work on a problem that is different each time we activate it. Think about it. How useful would a square root routine be if all it could do is calculate the square root of two. But a square root routine that can calculate the square root of any number, well that it a very useful routine.
All we need to do is come up with a way to hand the routine a specific value to work with each time we activate it.
That way is through a parameter list.
The formal specification of a function looks like this:
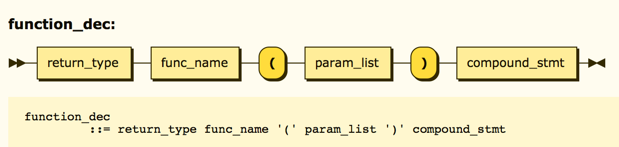
Where:
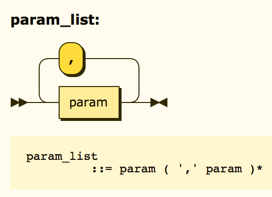
And:
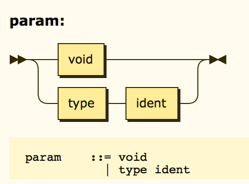
Formally, when we call a function, we will provide values for the parameters specified in the parameter list defined on the function declaration. Beginning programmers often get confused by the names on the declaration, thinking that those names mean something in the context of the code where they call the function. That is not true.
The names that appear in the function declaration belong to the function itself. Formally, those names are local to the function, and belong inside the function. When the function code is running, those names are variables with values set by the calling code. Back to our square root example, if the caller wanted the square root of five, and the declaration of the square root function called the parameter variable data, then when the function ran, data would have an initial value of 5. As the function ran, that value could change, and the calling code would not know that happened.
This is called “call by value”. The calling code effectively copies in a value into the function code variable. The function code has no ides where that value came from and cannot modify any values in the caller’s code area. The caller’s world is completely isolated from the function’s world, which is often a good thing. i
The return statement¶
If a function has a non-void return type, it must also have a return statement somewhere in the body of the function.
The value returned on that statement is the value returned by that function, and the type of that value must match the promised return type!
You can have multiple return statements in a function. They all act the same way.
When you reach any of them, the function stops immediately, and you go back to the point where you called this function. You were probably in the middle of an expression waiting on a value of some kind. The returned value from the function is the value you were waiting for, and it will be processed in the expression, and the expression will continue to be worked on until it completes.
If a function does not return a value, it is called on a line by itself. Activating the function is all we need to do. Its effect is to do its work, then terminate. Whatever side effect it may product is what we expect from it, and nothing else. Our “message” function returns no value, and the side-effect is that message appearing on your screen!
Function Prototypes¶
So far, we have looked at complete function declarations. You provide everything needed to build the actual function. There are times when we do not want (or need) the complete function declaration, just enough to actually call the function!
C++ has a simple rule: the compiler needs to know everything needed to check proper use of a name before you can use that name. In the case of a function, all the compiler needs to know are these three things:
The return type of the function
The name of the function
The parameters needed to call the function (not the parameter names, just the types will do, although it is common to include names)
This is everything on the first line, up to the open curly brace. We can write this line, and end it with a semicolon, then use the function as we wish from that point on in our code.
That single line is called a “function prototype”.
Of course, eventually, we need to provide the function body, and we do that by placing the full declaration in our code file at a later point. The compiler will check this declaration against the original line it saw earlier to make sure you did not mess things up.
Software Contracts¶
The function prototype” is a kind of contract between the writer of the function and the user of that function. That could be two different programmers! Once both parties agree on what the function will look like, one can go off and write code that uses the function, and the other can go off ans write the actual function code. When we glue both parts together, they will work!
Header Files¶
If you write a function in one file, and want to use that function in another file, it is common to place your function prototype line in a separate file called a “header file” whose name ends in “.h”. You “include” this file in any program that needs to use the function. That includes the file where the real function declaration lives as well, again so the compiler can check things.
We saw examples of doing this in our earlier lecture when we broke up a single-file program into several files.
